How to Tell if Google’s Crawling of Your CSS or JavaScript is Blocked, and How to Fix It
Here's how you can determine whether your website is blocking Google's bots from crawling your JavaScript and CSS files, and how to fix it.
Get a Free Marketing Analysis and Consultation
Nowspeed can review your Website, SEO, PPC, Email or Social Media Campaigns and identify ways to make an immediate impact!
A few years ago, Google updated their crawler to include the rendering of JavaScript and CSS files to better determine the content and structure of a web page. This means that instead of just looking at your website from a text-content perspective, their robots look at the script and style as well, and can better understand things like on-page advertising, mobile usability and more.
On top of that, they further updated their webmaster guidelines to include this rendering as a factor in determining your SEO: “Disallowing crawling of JavaScript or CSS files in your site’s robots.txt directly harms how well our algorithms render and index your content and can result in suboptimal rankings.” Or, as Google’s Pierre Far put it, “By blocking crawling of CSS and JS, you’re actively harming the indexing of your pages.”
So, how do you determine if your CSS and JavaScript is being blocked?
It’s actually pretty simple, now that Google has updated its crawler to render pages. Google allows you to crawl and render your page directly in your Search Console account. Here’s a breakdown, using a website that we just began monitoring and working on, of how to check and determine what the issue is:
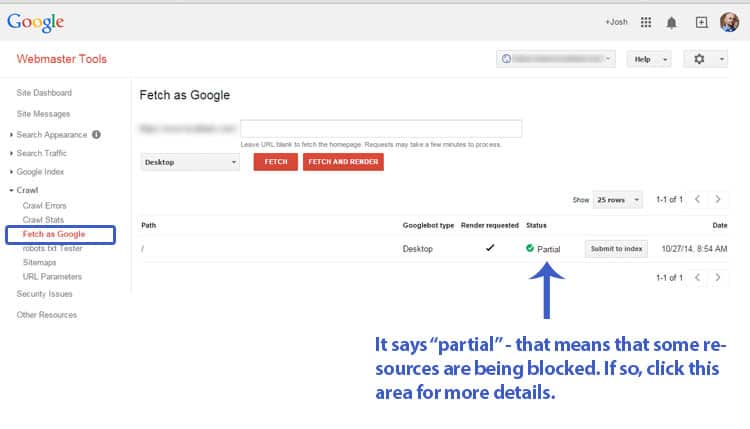
This is found under the “Crawl” category in your Webmaster Tools account.
Visit the “Fetch as Google” menu item in the Crawl category on your left. From there, if you’re looking to check your home page, leave the URL field blank and press “fetch and render.” It will take a minute or two to run, but after it’s done, you’ll get a result under the “status” that tells you whether there are problems. Do this for both desktop and mobile when you’re checking – the dropdown box next to the “Fetch” button is where you’ll see this option. If the results say “Complete” – then congratulations, you’re good to go! Otherwise, the results will say “Partial” and you’ll have to go one step further to take a look at what’s not being rendered properly. In the case of this sample site, well, you’ll see:
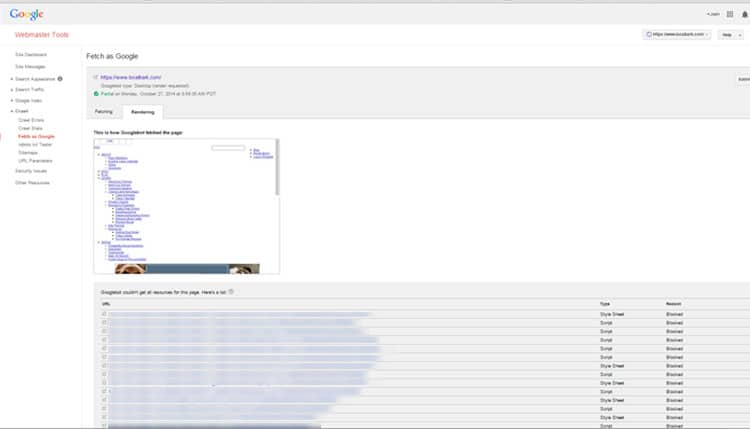
This site is not rendering properly – too many files are being blocked.
This site is having a lot of issues, as you can see by the fact that it’s not showing properly in the display screen (this should match the way you see your site when you visit it in your browser), as well as the list of items under the “Google couldn’t get all the resources for this page” area. This is a list of all the files that the Googlebot couldn’t access in order to determine the style and content of your site.
So how do you allow google access to CSS and JavaScript files?
This is primarily done through your robots.txt file. There are a few other things that could cause issues. For instance, if you are using external fonts and the CSS affiliated with them is not accessible, or your JavaScript file has been moved, etc. But the number one reason these errors appear is the robots.txt file. In the case of this example website, the webmaster blocked robots access to all subdirectories that didn’t contain images or necessary files on the website, likely due to security concerns.
The easiest solution is to allow the robots to access the directories that contain the necessary CSS and JavaScript files, while keeping all other directories blocked. For the webmaster, it would look something like this (this is a hypothetical example, do not copy and paste this text into your file as the directories will changed based on the structure of your site):
User-agent: *
Disallow: /admin/
Disallow: /blocked-folder/
Allow: /blocked-folder/css/
Allow: /blocked-folder/js/
You can block the main folder, and allow subfolders to still be crawled. Alternatively, if you want to allow only Google’s robot to crawl those folders, then your code would look like:
User-agent: *
Disallow: /admin/
Disallow: /blocked-folder/User-agent: Googlebot
Allow: /blocked-folder/css/
Allow: /blocked-folder/js/
And so on. The more detailed way to do this would be to modify your site’s structure to centralize all CSS and JavaScript files into one area that you allow the robots to access. This certainly would be an easier way to manage this process in the long-run. Also, if you use a CMS like WordPress or Joomla!, you’ll have to refer to their user guides to see how the file system is structured to properly manage your robots.txt file.
Once you successfully edit your files, you can process the fetch and render again, and if all is well, you should get a result like the one below for this website:
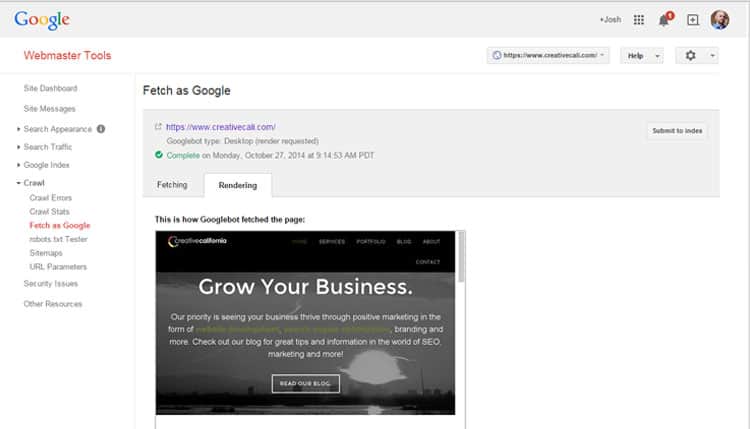
A successful fetch and render shows your site how it looks in your browser, and has the little “complete” icon.
If you have recently experienced a problem in your search rankings related to the Panda algorithm, but you feel your content is stellar, perhaps this is something you’re dealing with. Yoast discussed this issue years ago in a post about Google Panda and blocking CSS and JavaScript, and went into a little more detail showing a case study for recovery. If you are still having trouble, don’t hesitate to contact us, or give us a shout in any of our social media accounts and we’ll see if we can get to the bottom of what’s going on with your site!
So let's
talk.
We're always excited to dig into the details of your company and what strategy can help you meet your goals. So let's talk and lay out a plan for success!